How Powerful are Graph Neural Networks?
21 Oct 2019 Graph neural networksGraph neural networks (GNNs) is a framework that allows to learn representations in a graph. This paper (Xu et al., 2018) discusses previous architectures, analyses their power of representation and presents their own GNN which is maximally powerful under certain constraints.
GNN architecture
In this NN architecture we learn to predict a vector representation for each node in a given graph. Each node \(v\) in this graph \(G=(V,E)\), with a fixed representation of nodes and edges, contains a vector of real numbers \(X_v\) that changes in order to learn one of the following: (1) Node classification, where given a classification \(y_v\) for each node and a function \(f\), we learn \(X_v\) such that \(f(X_v) = y_v\); (2) Graph classification, where given a set of graphs \(G_1,...,G_n\) classified by labels \(y_1,...,y_n\) and an aggregation function \(h\), we learn \(X_v\) for each node such that the aggregation of each graph matches its label i.e. \(h(G_i) = y_i\).
If we only want to learn the representation of the nodes (case 1), we define two operations, aggregate and combine (as in the image below) that tweak the representation of each node with respect to its neightbours. This functions are learnable and are run a certain number of times (K) so no full convergence is required. In the case we want Graph classification (case 2), a readout operation is implemented as well, which maps the set of nodes to the same space as the graph classes. After the final (K) iteration of aggregate & combine operations in the graph, the loss of the nodes/graph is calculated w.r.t. the target classes and the aggregate & combine functions are updated by calculating the derivatives of the loss to the learnable parameters (the matrix W in the example below). Then, iterations are repeated until we get the target representations.
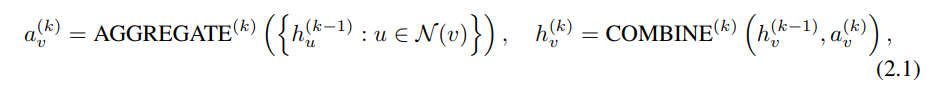

Analysis and limitations
To analyse how powerful GNN architectures are, the authors propose the Weisfeiler-Lehman (WL) test:

Basically, an embedding (i.e. a function that maps the nodes of a graph to a vector space) has to map the nodes of different graphs to different vectors. The difference between this test and normal graph isomorphism is that it does not require isomorphic (i.e. structurally equivalent) graphs to be mapped to the same vector. This has been shown to work well in most cases (except regular graphs).
GNNs are at most as powerful as the WL test (otherwise they would solve graph isomorphism in polynomial time, a complexity problem not solved to the date of this post, although not-confirmed quasipolynomial time algorithms have been shown in the literature). Still, they can be exactly as powerful as the test if the following conditions are met:

GINs
Next, the authors present Graph Isomorphism Networks (GIN) that satisfy the theorem above. Namely, GINs can model any Graph classification (case 2) problem and obtain the representation of each node, such that (by theorem) if two graphs are different, nodes are guaranteed to be assigned different representations. The nodes, edges and node embeddings are modeled as explained before, what they define is a particular aggregate & combine function that satisfies the theorem.

They also suggest a readout function that works well in practice from previous literature:

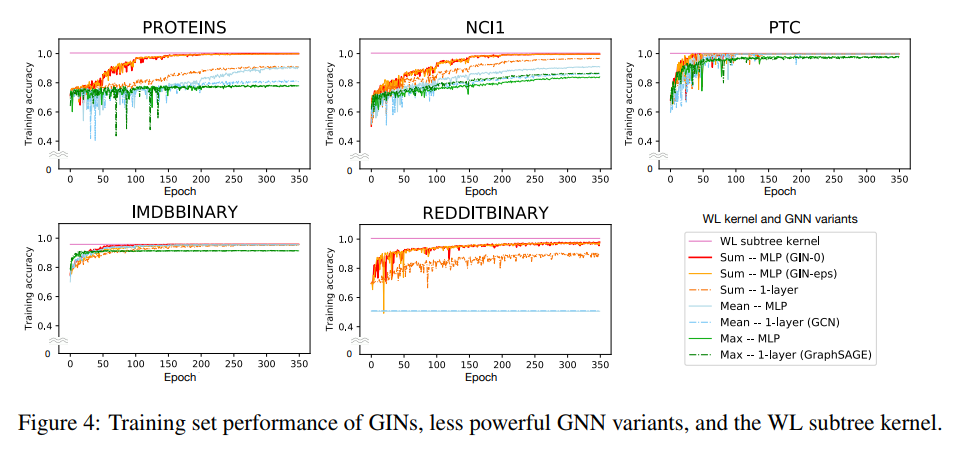
Finally they compare the power of their architecture to others and test GINs in practice vs. GCN and GraphSAGE.
Conclusion
-
Developed theoretical foundations for reasoning about the expressive power of GNNs.
-
Designed a provably maximally powerful GNN under the neighborhood aggregation framework.
-
Achieved state-of-the-art performance.
References
- Xu, K., Hu, W., Leskovec, J., & Jegelka, S. (2018). How Powerful are Graph Neural Networks? CoRR, abs/1810.00826. http://arxiv.org/abs/1810.00826